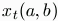 be value of the connection from a to b at time t. We interpret this value as the price b would pay for one of a's stories, or more generically, the "confidence" b has in a to send out a good story. This value will depend on the past success b has had publishing a's work in terms of increased advertising revenue, for example. Let the "confidence network", Xt, be the N x N matrix of these values at time t. Notice there is no reason to expect this matrix to be symmetric; a's offer to b need not be same as b's for a.
be value of the connection from a to b at time t. We interpret this value as the price b would pay for one of a's stories, or more generically, the "confidence" b has in a to send out a good story. This value will depend on the past success b has had publishing a's work in terms of increased advertising revenue, for example. Let the "confidence network", Xt, be the N x N matrix of these values at time t. Notice there is no reason to expect this matrix to be symmetric; a's offer to b need not be same as b's for a.
In addition to the network, there is a set Z of possible news stories. In their capacity as media outlet, each node n has associated with it a function 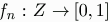 which reveals to that outlet the "true" value of a story sent to it. Reporters sending stories to node n initially know nothing about
which reveals to that outlet the "true" value of a story sent to it. Reporters sending stories to node n initially know nothing about 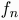 but will have the opportunity to learn about it. They learn through the feedback sent back over the connection.
but will have the opportunity to learn about it. They learn through the feedback sent back over the connection.
Sending a story through the network is not free. We assume that a reporter pays fixed cost c for each other reporter to which they send a story. Roughly speaking, in the long run, it will not be worth sending stories to nodes whose offer price is above this cost.
We assume that a reporter can only send out one story in each time step. Thus each reporter's problem in every time step is to select a story and list of recipients. However, since the value to the reporter of a particular selection depends on how the reporter distributes it, the value of the first decision depends on the second.
Before play begins, each reporter,n is endowed with an initial stock of guesses Gn,0. Elements of Gn consist of a story, 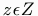 , and a recipient list,
, and a recipient list, 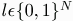
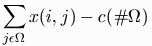 where
where 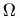 is the recipient list.
is the recipient list.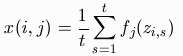 .
.